阿里云OSS对象存储入门(PY)
为什么要写这一篇博客
我在做memedroid_translator的时候,会有使用serverless或者GitHub Actions的需求,这就要求我需要有一个地方,能够根据url把爬取的图片持久化。如果直接上传到服务器,变成一个网络url,那我其实还不如直接用原网站的url呢;同时我之前询问了Kimi,它给出的解决方案也是使用阿里云OSS这种弹性容器,可以按需储存。它的解释是这样的:
Q: 使用GitHub Action来运行爬虫并存储图片,是直接存到自己的服务器中好还是存储到oss好
A: 结论先行:GitHub Actions 跑爬虫存图片,优先用 OSS(或任意 S3 兼容对象存储),不要直接回写 GitHub 仓库,也不建议自己再维护一台服务器。原因如下:
维度 直接存自己服务器 存 OSS/Cloudflare R2 等 网络出口 Actions 先下载到 runner,再 scp/rsync到你服务器,走公网, 速度慢、易掉线直接用官方 SDK 走内网上传, 稳定、秒级完成 存储成本 服务器硬盘自己扩容, 费用线性增加 Cloudflare R2 每月 10 GB 免费,阿里云 OSS 按量几分钱/GB, 几乎白嫖 运维成本 要管机器、备份、磁盘告警、SSH 密钥、防火墙…… 一个人全包 全托管, 零运维 Action 时长 上传大文件占 runner 时间, 2000 min/月免费额度快速消耗 上传耗时短, 节省免费时长 仓库体积 如果误提交到 Git,仓库迅速膨胀, GitHub 1 GB 软限制,5 GB 硬限制 文件不进仓库, 仓库保持轻量 权限/安全 服务器密钥硬编码在 Secret, 一旦泄露整机被日 OSS 用临时 STS 或最小权限子账号, 泄露只丢一桶图
因此我准备使用OSS来进行存储。同时由于阿里云的网站使用起来非常复杂,所有的服务、控制台、接口全在一块,非常的不方便,同时接口也有很多没有解释到位的地方,因此我就准备写这一篇博客,来讲一下自己在使用阿里云OSS的时候碰到了什么坑。
一些基本定义介绍
在这之前,我们应该先讲一下如何获取一个OSS容器。
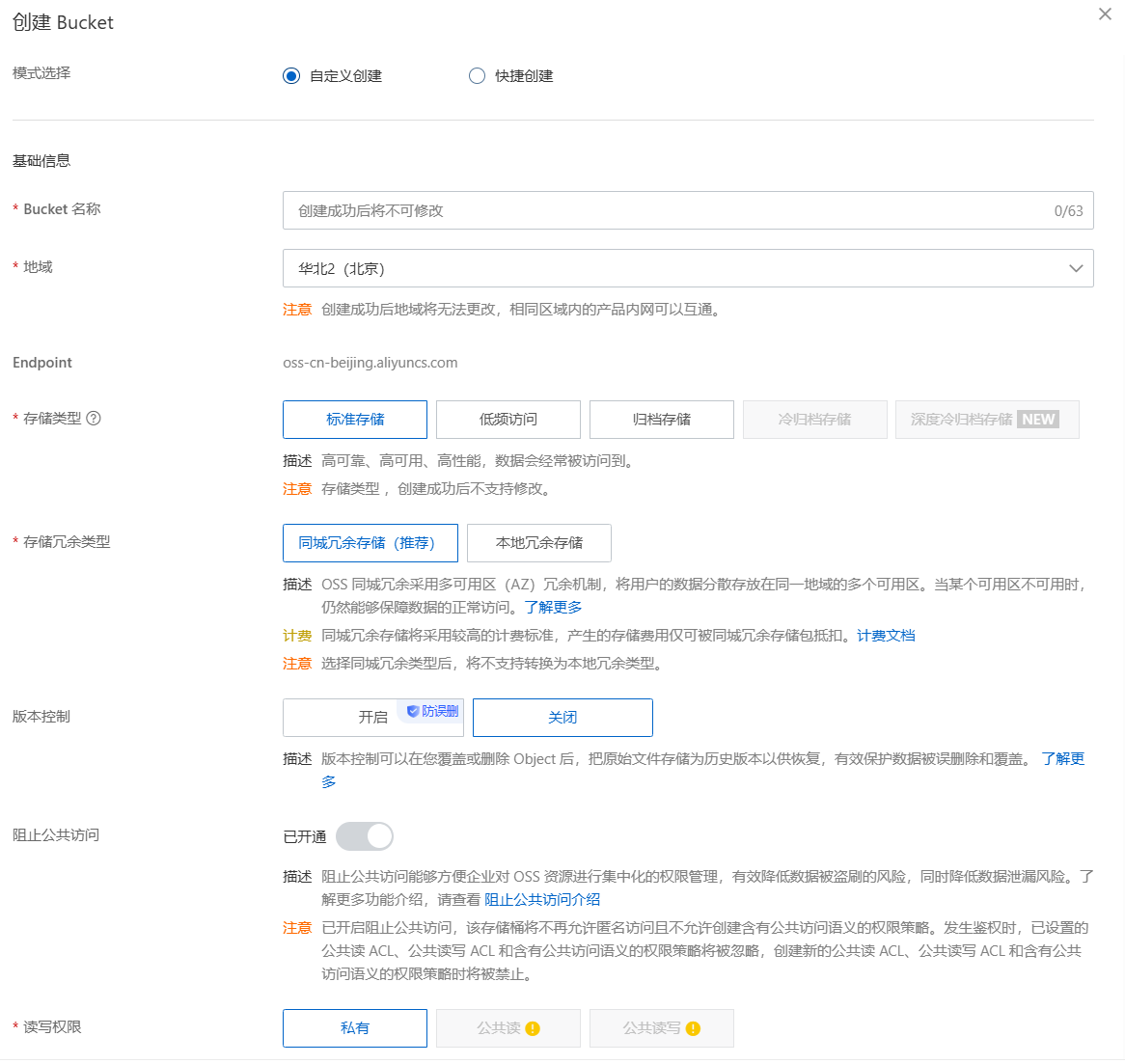
注册阿里云账号之后,来到阿里云OSS容器的控制台页面,点击“创建Bucket”,就会看到下面这张图。设置好自己Bucket的配置,然后就可以了。
拥有一个Bucket之后,我们需要注册一个RAM用户并获取API Key。来到RAM访问控制的控制台界面,点击创建用户,添加一个用户。一定要牢记自己的Key和Secret,并为对应的用户分配能够操作OSS容器的权限,这样就成功注册一个能够用代码操作OSS的用户了。
- Bucket容器:就是一块存储空间,抽象成一个容器罢了。
- 对象Object:对象(Object)是OSS存储数据的基本单元,也被称为OSS的文件。和传统的文件系统不同,Object没有文件目录层级结构的关系(摘自阿里云官网)。
- RAM用户:操作OSS的主体,系统判断能否进行某种操作看的就是该用户是否有对应权限。
顺便说一句,阿里云OSS的库(Python SDK V2)名叫alibabacloud_oss_v2,在本文中的import作如下规定:
1 | import alibabacloud_oss_v2 as oss # 同步 |
连接OSS弹性容器
在连接一个容器之前,要先创建一个Client,传入合法的access_key_id和对应的access_key_secret,设置所在地区并读取配置。我知道的方法有以下几种。
直接读取环境变量
这个方法是官网给岀的方法,要求系统中有OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET这两个变量。
1 | credentials_provider = oss.credentials.EnvironmentVariableCredentialsProvider() |
其中,credentials_provider是凭证提供者变量,cfg是配置项字典。
传入静态变量
这是我在写memedroid_translator时所使用的方法,access_key_id和access_key_secret通过传字符串的方式给cfg。
1 | credentials_provider = oss.credentials.StaticCredentialsProvider( |
关于cfg.region
这是你的bucket所在的地区,必须要对应上,通常来讲是cn-+城市名,例如华北2在北京,那么该地区的region就是cn-beijing。至于海外的服务器,由于我手头没有海外的服务器,也没看到阿里云官方的文档,因此我也不知道是啥。
上传文件
一次上传文件操作是通过构建一个PutObjectRequest来完成的,有一些是必填字段,剩下的则是选填字段,这里列出必填和一些重要的选填字段。
必填:
bucket:str,你要上传的目的容器名。key:str,对象的键名,说白了就是文件名。
选填:
body: 对象的主体,支持str、bytes、IO[str]、IO[bytes]、Iterable[bytes]。- …(其他的我还没用过,文档也没写,只能等以后探索了)
传入一个字符串文本sample_string的代码如下,我们先创建一个PutObjectRequst,然后用client.put_object方法来传:
1 | put_object_request = oss.PutObjectRequest( |
当你知道文件类型的时候,你也可以直接传bytes,配上文件名,就可以达到上传图片的效果。我不知道这是否是最佳实践,因为我在文档里没看见。但我在memedroids_translator中就用的这个,确实可以用。
如果想创建文件夹的话,直接修改key参数即可。注意不需要用什么Path之类的,OSS里用的都是/。
1 | correct_key = 'a' + '/' 'b' # 正确 |
下载文件
和上传文件类似,下载文件要构建的是一个GetObjectRequest,这里要传的参数就只用容器名就可以了。
1 | get_object_request = oss.GetObjectRequest( |
得到result后,你需要通过它的body属性来获取,因为result的GetObjectResult对象本质上是一个“响应包装器”,而读取又有两种方式,完整读取和分块读取。虽然我没用过分块读取,但由于官方比较推荐,所以还是放过来吧,下次做项目的时候用用。
1 | # 完整读取 |
文件名查找
不是在任何情况下我们都能知道文件的名字的,因此查找合适的文件名也是一个刚需。OSS也给了我们这个功能,利用ListObjectsV2Request(我也不知道为什么是V2,也许是SDK版本是V2吧)就可以了。
ListObjectV2Request的一些比较重要的参数如下:
bucket:str,容器的名字。prefix:str,你要查找的文件名字的前缀,不能以/开头,如果为空则返回所有文件的key。max_keys:number,返回文件的最大数量。continuation_token:str,查找的起始位置。
其中,prefix和delimiter参数还可以进行组合使用。因为prefix默认是递归查找的,修改delimiter就可以控制是否是递归查找了。例如,一个Bucket中有三个Object,分别为fun/test.jpg、fun/movie/001.avi和fun/movie/007.avi。如果设定prefix为fun/,则返回三个Object;如果在prefix设置为fun/的基础上,将delimiter设置为正斜线(/),则返回fun/test.jpg和fun/movie/(摘自阿里云官方文档)。
1 | get_objects_request = oss.ListObjectsV2Request( |
总结
本文讲述了我在刚使用阿里云OSS对象存储的基本方法,能够实现基本的上传下载和查找功能。如果以后用到了更多的功能,还会继续分享,进行一个知识的沉淀的。在代码层面OSS存储其实并没有比本地存储更加的简便,但是确实更适合在github actions这种场景上跑。同时由于阿里云的文档比较分散,以后更新这篇文章的时候,就可以把文档之类的整合起来,方便查找和使用。
参考链接
- 阿里云对象存储官方文档
- 阿里云对象存储API参考(虽然页面上的导航显示的是他是上面那个链接的一部分,但是其实是找不到的)
- alibaba_cloud_oss_v2 Documention
更新记录
- 2026-1-6 发布第一稿
- 标题: 阿里云OSS对象存储入门(PY)
- 作者: Baobao0824
- 创建于 : 2026-01-06 20:04:08
- 更新于 : 2026-01-18 19:53:50
- 链接: https://blog.baobao0824.top/代码/原创/阿里云OSS对象存储入门(PY)/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。