Langchain快速入门-BlockStack0x001
原链接:
写在前面
什么是块叠?就是从他人优秀的知识总结中搬出一块来,叠到自己的技术栈上;Put a block of knowledge onto your own coding stack。通过一篇文章(视频、书籍等),发现自己技术栈中的空缺,并发散开去,作最大化的填补。遵循原文顺序、最佳实践优先、扩展思维含量,这就是BlockStack的理念与追求。每月的1号和15号,我都会(尽量)发布一期,或者完善之前的部分出一期新稿,希望能尽可能聊得彻底、翔实。
这是一个系列的文章,一共有六篇。介绍了Langchain的基本使用方法。对于Agent使用越来越广泛的今天,了解这些有很重要的意义。同时这篇文章的内容也不是最新langchain版本中官方所推荐的最佳实践了,因此也需要对文章讲的知识进行更新。这也是我选择这些文章作为本期BlockStack的理由。
(一)运行你第一个LLM模型
Langchain是一个开源库,可以让你以最快的方式来构建一个大模型应用,其可以将工具组件、提示词组件和大模型组件等有机融合,可以让一个AI过程抽象成一个个组件的调用流程。同时让大模型配合其他的代码来进行使用,从而达到1+1>2的效果。它支持python和js/ts语言。它通过一系列的规定,来对一个大模型的过程进行标准化。
多说无益,我们先来看一个最小的demo,然后再解读这个代码。为了和原链接一致,我们在这里用的都是python代码。
在demo之前,我们首先要进行一个安装。在当前版本(langchain-core==1.2.8)中,我们需要安装核心langchain,还有对应的供应商的专用包,二者缺一不可:例如使用openai,就需要安装langchain-openai。在本文中,我们使用硅基流动的模型(因为我还有几块钱的免费没用完),它可以直接使用openai的包,参考文档在这里。
1 | from langchain.agents import create_agent |
这是官网的示例。我们可以看到,首先我们先通过create_agent函数创建了一个AI助手,给了他一个工具也就是get_weather、模型名称和系统提示。然后直接调用这个Agent。为了能够兼容硅基流动,我们需要对代码进行改造,让它更适合这个供应商,例如下面的代码。
1 | from langchain.agents import create_agent |
目前很多市面上的参考资料(包括笔者最后列出的部分参考资料),根本就没有完全理解Langchain的设计哲学。例如在一些文章中,它会让你直接通过供应商模型类的构造函数来初始化模型,原文章的作者使用了ChatTongyi类的构造函数。实际上官方并不推荐这种过于具体的模型构建方式,取而代之的是官方的init_chat_modelAPI。同时官方文档中的model参数直接给的是模型名称,这个就是一种比较偷懒的写法,对于国内这种无法访问原生URL的环境来说,先定义一个model再传进来反而是比较有利的选择。
上述的代码其实并没有走完一个大模型工作流的完成流程。我们先来剖析一下一个Langchain工作流的运行流程,然后在最后我们再补上一个完整的示例代码。
- 创建模型
init_chat_model函数是Langchain官方推荐的一个通用的初始化模型的方式。它有以下的一些常用参数:
model:模型名称,在不给出provider的情况下,函数也会根据模型名称来自动推断provider。model_provider:模型的供应商,如果你需要显示指定,不依赖自动推断的话,就需要给这个参数了。具体支持的列表可以参考这个链接。**kwargs:这个就是给每个不同的模型和供应商准备的自留地了,根据供应商的不同,所需的名称和类型数量之类的也不相同。例如上文的代码中的api_key和base_url。可以参考这个链接来查看具体的细节。
- 消息设置
prompt就是大模型所获得的提示词,你可以将他看做一种输入。在Langchain中,模型上下文的基本单位是消息(Messages),模型的所有输入和输出都是借助一条条消息来实现的
在Langchain中的消息分为三类,分别代表着三种不同的角色:system、user和ai。他们对应的类和作用说明如下表所示。
| 角色名称 (Role) | 对应的类 | 作用说明 |
|---|---|---|
| system | SystemMessage |
系统提示词。用于设定 AI 的“人格”、专业背景、行为准则或约束条件。它通常优先级最高,决定了后续对话的基调。 |
| user | HumanMessage |
用户消息。代表人类发送的内容。这是模型需要直接回答或处理的问题。 |
| ai | AIMessage |
AI 消息。代表模型之前的回复。在构建多轮对话(带记忆)时,需要把模型之前的回复传回去。 |
那么我们到底如何声明一个Messages呢?有下面三种方法。
首先是直接一句话的文本提示,例如当你很简单的调用或者不需要对话上下文的时候,直接塞给模型一个字符串就行。
1 | response = model.invoke("写一个关于春天的俳句") |
如果你需要上下文记忆等更复杂的使用,那么你就可以通过字典或者消息对象列表来进行更精细化的使用。笔者本人更喜欢使用消息对象列表,因为看起来比较简洁。虽然这里两边的代码都会给出,但是后续还是尽量不适用dict。
1 | # 消息对象列表 |
如果一个模型能够支持工具调用的话,那么我们还可以使用ToolMessage类来表示工具消息。等到后面的文章中我们还会再更加详细的介绍。
下面我们来介绍一下模型的输出。通常来讲,如果直接让模型进行输出,那么模型返回的是一个AIMessage类,里面包括了content等内容。不过同时,我们也可以让模型遵循特定的结构来进行输出。在Langchain中,模型的结构化输出分三种,一种是Pydantic Model,一种是TypedDict,还有就是JSON格式了。由于笔者目前不了解Pydantic和typeddict,因此在本文中统一使用JSON格式。JSON的内容可以根据自己的喜好来进行编排。例如我想直接返回电影《功夫熊猫》的基本介绍。
1 | json_schema = { |
输出的结果为{'director': '马克·奥斯本', 'rating': 8.0, 'title': '功夫熊猫', 'year': 2008}。类型为dict。
我们可以看到,如果想用结构化输出呢,我们需要先给模型传入这个结构化输出的模板(json_schema)同时也可以指明输出的方式(可选),使用模型的with_structured_output方法,它会返回Langchain的Runnable实例,关于Runnable我们留到后面再讲。之所以不直接修改原模型,是因为这样可以利用同一个模型创建多个不同的schema版本。而Langchain中结构化输出,本质上是调用了各个模型提供商的结构化输出API,以openai举例,在GPT-4o及以后,OpenAI提供了Structured Outputs(约束解码)机制,在模型生成token的时候实时验证,如果下一个token会破坏schema的格式,直接禁止生成,官方保证输出格式100%符合。因此所有的输出都是严格结构化的。
模型除了使用invoke方法直接调用之外,还有以下两种方式,Stream(流式)和Batch(批次)。流式输出通过调用stream()函数返回一个迭代器,这样就能在每次输出的时候产生一个chunk,你就可以用循环来实时处理每一个块,然后将他们汇总形成完整的消息。
1 | full = None # 完整的文本,类型为 None | AIMessageChunk |
batch可以批量处理一组独立请求到模型中,这样可以显著提升性能并且降低成本,因为处理可以并行完成。
1 | responses = model.batch([ |
在默认情况下他只返回整个batch的最终输出,如果你想在每个任务完成的时候就输出,就可以使用batch_as_completed()流式传输结果。
1 | for response in model.batch_as_completed([ |
(二)chain链的应用
我们在上一章讲了,使用模型的with_structured_output方法会返回Langchain的Runnable实例。若干个Runnable对象可以组合在一起,就可以创建chain链。为什么要这样做呢?因为这个类实现了所有的处理和输出方式,包括同步、异步、批处理和流式输出。
Runnable的两个主要的组合原语是RunnableSequence和RunnableParallel,前者是串行的,依次调用一系列Runnable,每个Runnable的输出都作为下一个的输入;而后者是同时调用若干个Runnable,每个对象的输入是一样的。
原文中给出了直接利用Runnable对象进行任务处理的示例。事实上,在1.0.0版本发布后,Langchain官方已经不再支持这一写法,所有旧的chain使用方式都已经被新的高级抽象工具所取代,比如我们可以直接用langgraph。因此这里就不过多介绍了。
(三)搭建RAG知识库
知识库可以让大模型在运行的时候有外部资料可以进行参考,同时也能减少模型的幻觉。
为了构建RAG知识库,我们首先需要加载数据,在Langchain中,这是通过Document Loaders(文档加载器)实现的。在langchain_community中有若干的documents_loader类,例如加载网页链接的WebBaseLoader。它能够从网页URL中加载HTML,然后可以自定义解析文本的条件。
1 | import bs4 |
这篇文章讲述了小智的皮卡丘在动画中的经历,有很多琐碎的信息(例如在哪一集中皮卡丘做了什么事情),同时文章长度非常的长,无法通过对话的形式放入到上下文窗口中。因此我们需要对文档进行拆分。通常来说文本拆分和切片有以下三种方法:按字数切、按句切还有递归切片。这几种方法没有绝对的好坏之分,可以根据你的实际需求来进行选择。langchain_text_splitters中提供了递归调用的RecursiveCharacterTextSplitter他会递归对用常用分隔符拆分文档,直到每个块的大小都合适。
1 | from langchain_text_splitters import RecursiveCharacterTextSplitter |
运行之后发现,整个文档被切成了37个块。每块的大小为1000字。
在文本拆分完之后,我们就需要进行向量的嵌入,来让大模型能够在运行的时候搜索。这个时候就需要自己选择合适的向量存储嵌入模型了。由于我们在国内不太好用OpenAI自己的词嵌入向量,因此我们改用智谱的,正好langchian_community里面有智谱的向量嵌入模型。那有人可能会问了,你之前的模型是DeepSeek的,怎么能使用智谱的词向量模型呢?这是因为在RAG工作的过程中,两个模型是同时工作的,LLM收到的是embedding模型给出的纯文本,而不是向量本身。所以两个模型只要都能用文本进行沟通,那么就没问题。最后得到的词向量我们就存储在内存中了。完整的代码如下
1 | from langchain_community.embeddings import ZhipuAIEmbeddings |
输出的结果为['09dc58a0-edf1-4328-a551-506b0e24113d', '2ddc9ca0-48d3-43e4-ab75-c5f3784da790',...]。
这几步全部完成之后,我们就可以创建一个RAG助手了。让LLM使用RAG有两种方式,第一种是先运行搜索,让搜索结果作为LLM的上下文来使用,这种方式操作快延迟低但是比较缺乏灵活性;另一种方式就是让RAG查询作为一种工具,那么LLM就只会在需要的时候进行搜索,但是这样的话模型的延迟可能就比较高。在本章中我们先使用前者,后者将会在下一章的最后来进行演示。
第一种实现方式实际上是使用了dynamic_promopt,这实际上是一种middleware(中间件)。中间件会在模型执行的每一步前后都暴露钩子,能够让中间件进行执行。Langchain官方预定义了一些中间件,其中有不区分模型服务商的,也用某个模型提供商特有的。当然了你也可以自定义中间件,来实现你所需要的功能。
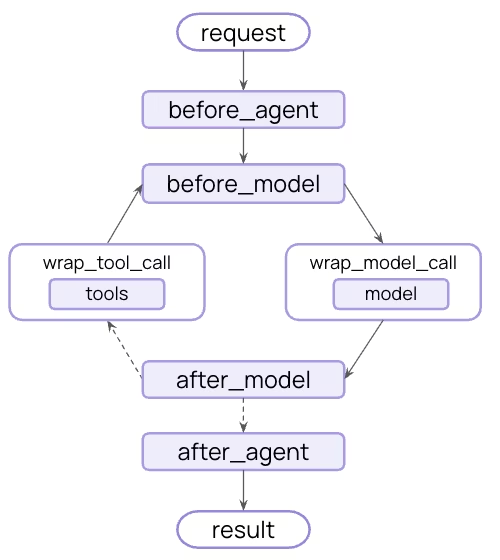
中间件的本质是一个函数,我们使用@dynamic_prompt装饰器来包裹一个函数,就可以根据模型的请求生成系统提示。
1 |
|
这样的话AI的结果就会遵循知识库中的知识了。
小智的皮卡丘在道馆战中曾被以下宝可梦击败:\n\n1. 冷水猴(三曜道馆) \n - 地点:三曜道馆 \n - 对手:寇恩 \n - 细节:因冷水猴速度过快未能命中攻击,皮卡丘连一击都未击中就被打败(《三曜道館!VS爆香猴、冷水猴、花椰猴!!》)。\n\n2. 青藤蛇(非道馆战,但属劲敌修帝的宝可梦) \n - 地点:修行对战 \n - 对手:修帝 \n - 细节:尽管恢复了电击能力,仍不敌修帝已进化的青藤蛇(《勁敵對戰!強敵轻飘飘!》)。\n\n3. 耿鬼(家缘道馆) \n - 地点:家缘道馆 \n - 对手:梅丽莎 \n - 细节:经过激烈对战最终落败(《家缘道館战!VS梅丽莎!!》)。\n\n4. 舞天鹅(吹寄道馆) \n - 地点:吹寄道馆 \n - 对手:风露 \n - 细节:电系招式被水流环无效化,空中战术失败后被连续攻击击倒(《吹寄道館VS風露!空中決戰!!》)
(四)搭建强大的AI Agent
Agent是将Model和工具结合起来的产物,他能创建各种任务,自己决定使用什么工具并查找解决方案。一个LLM Agent会循环运行各种不同的工具来实现目标,一直运行到满足停止条件为止。虽然Model本身就能够调用工具,但是它并不能用来帮你处理工具调用的循环,你必须自己处理工具返回的结果。
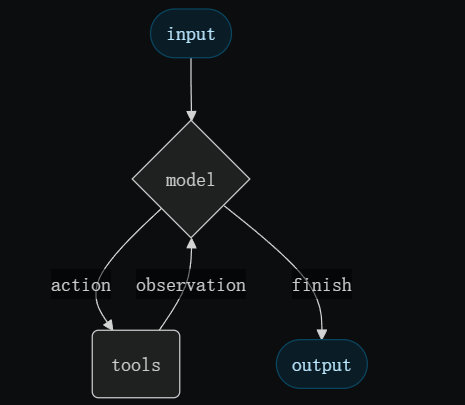
工具是一个可调用的函数,有着清晰的输入和输出,然后传递给聊天模型,模型就可以根据上下文决定合适调用工具。要创建一个工具,最简单的方法就是用@tool装饰符,同时函数的docstring会成为工具函数的描述,能够帮助模型来了解何时使用。同时要注意,不是所有的模型都能够调用工具的,比如Qwen/Qwen3-VL-8B-Instruct,如果你尝试调用工具,那么你只能得到空输出。
1 |
|
观察输出结果,可以看到模型先输出空字符串,然后进行工具调用,返回了一个ToolMessage然后再输出AiMessage的内容,即广州的天气是晴天!。
那么根据上一章埋的坑,我们这一章就使用@tools来以另一种方式实现RAG关系库的查询
1 |
|
使用工具的话那么LLM自己会决定是否上知识库里面进行查询,就会更加的灵活
在道馆战中,小智的皮卡丘曾被以下宝可梦打败过:\n\n1. 舞天鹅 - 在吹寄道馆的空中战中被舞天鹅的多重招式击倒。\n2. 八爪武师 - 在超级级的对战中被八爪武师的“蛸固战术”打败。
(五)Langgraph应用,执行流程由线转图
Langgraph是Langchain的底层实现,提供了状态持久化、流式传输和人机交互等底层功能,Langchain的agent正是借助Langgraph来实现的。对于一般用户而言,两者搭配着使用才是最方便的,因此可以在自己的Python项目中直接安装langchain和langgraph。
官方文档给出的是一个拥有四则运算功能的agent,他用的是Claude,我们这里对其略作修改,使用上文的deepseek-ai/DeepSeek-V3模型。首先我们要先把模型和工具的代码写出来
1 | from langchain.chat_models import init_chat_model |
Langgraph有两种API类型,其一是Graph API(图API),更适合将agent定义为有节点和边的图;另一种是Functional API(函数式API),更适合将agent定义为单一函数。那么在本文中我们会将两种方式都体验一下,并且给出个人认为的优缺点。
在图API中,我们可以定义MessagesState类,用来存储消息和LLM调用次数;定义模型node,每个node都用于调用LLM,并决定是否调用某个工具;定义工具node,用于调用工具并返回结果
1 | # step2 定义状态 |
有了这些节点之后,我们还需要根据LLM是否调用工具,对节点的路径进行转移,如果模型自己选择调用工具,那么就进入工具调用节点,给模型返回工具函数的结果,否则的话就直接结束。
1 | # step5 定义节点跳转逻辑 |
一切准备就绪,接下来就可以构建工作流了,包括这个AI Graph中有什么节点和什么边,同时库中还自带一个将agent工作流程转换成图片的方法。
1 | # step6 构建工作流 |
接下来我们就可以进行调用了。
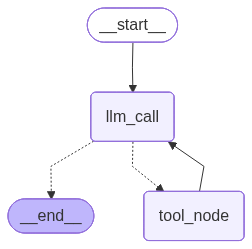
1 | # step8 模型调用 |
1 | ================================ Human Message ================================= |
函数式API的做法是将不同的操作看做不同的任务,由@task装饰器定义,可以让agent进行同步或异步的调用。
1 | # step2 定义调用LLM任务 |
在函数API中,代理是通过@entrypoint函数构建的,你不用再直接定义节点和边,只需要在一个函数内些循环或者条件语句即可。
1 | # step4 构建agent |
效果上是一样的,就我个人而言,我感觉还是后者更方便一些,毕竟节点比较好定义。不过还是那句话,除非你需要高度定制LLM应用,否则的话这些底层的使用其实我觉得没有多大意义,直接用Langchain的工具也是够用的。原文的示例讲的是一个利用RAG知识库的文章撰写任务,利用的是比较老的API,很多设计目前已经弃用了。
(六)实现多agent协作
虽然一个LLM基本就能解决大多数的问题,但是有的时候我们还是需要使用多个agent进行协作,才能发挥最大的效果。正好Langchain也为我们提供了这种能力。
在langchain中,我们主要有下面几种使用方式:次级代理Subagents、交接Hangdoffs、技能Skills、路由器Router以及自定义流程Cutsom workflow。这几种方式各自有不同的特点,可以根据下面几个维度来进行评判
- 分布式开发Distributed development:不同的团队是否可以独立维护组件
- 并行化Parallelization:多个agent是否能够同时运行
- 多跳Multi-hop:是否支持串联呼叫多个subagent
- 直接用户互动Direct user interaction:subagent是否能直接和用户对话
原文中构建了一个“查百度阿里腾讯的PE并计算平均值”的任务,这个任务的结构其实就类似于次级代理。因此本文中我们以这个模式为例进行学习。次级代理的工作流程如下:主agent会协调subagent作为工具,然后所有subagent返回的路由都经过主代理。subagent是无状态的,它们不记得过去的交互,所有的对话记忆都由主agent维护,而subagent是通过工具来进行调用的,并且可以并行执行。
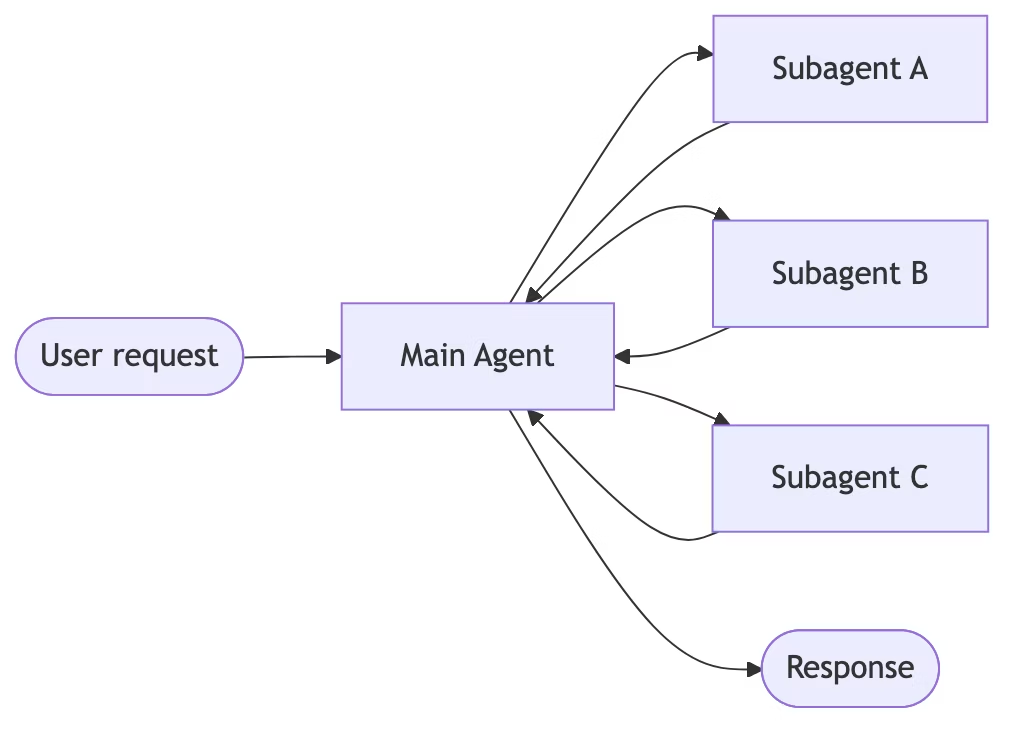
他的基本实现也很简单,你只需要定义一个新的subagent变量,然后把调用subagent包装在一个特定的工具函数中即可。
1 | from langchain.tools import tool |
为了方便这里两个agent都用同样的模型了。根据输出结果可以看到,主模型选择使用Subagent来进行调研的工作,而不是自己直接回答
拥有这些还不够,你还需要对自己的AI应用模式做出一些设计上的抉择,包括同步异步、工具模式以及subagent输入输出。
默认情况下,suagent之间是同步的,主agent会在每个subagent完成之后才继续。如果主agent的下一步操作依赖于subagent的结果时,那么应该使用同步。这很适用于具有顺序依赖关系的任务,同时实现起来也非常的简单,不过在所有agent完成之前用户看不到任何响应结果。当你需要同时运行多个独立任务的时候,就比较推荐使用异步输出了,在这种模式下,每完成一个任务,你的应用就需要通知用户任务已完成,比方说显示一个通知给用户看。
工具模式是使用次级代理协同工作的核心模式,首先你需要决定函数的设计方法:为每个subagent都设计一个工具函数,或者说你只使用一个工具函数来进行所有调用,这种方式也被称为“单调度工具Single dispatch tool”。这种方式能够获得更强的上下文隔离。
下面是一个单调度工具的例子,他使用了两个subagent,研究型和写作型的,注意到他只用了一个task函数,通过传入的参数不同来决定调用哪个subagent。函数中只会传入对于当前subagent的请求prompt,而不会有其他subagent的信息,这样就会有更强的上下文隔离了。
1 | from langchain.agents import create_agent |
注意到task函数需要传入subagent的名称,要在research和writer中二选一,因此建议在doc中直接写好参数的可选项,否则主agent会传入意外的参数(例如writing)导致程序出错。当然,为了避免产生这样的问题,你也可以直接在参数列表中加上枚举约束。
1 | # 混合继承,既兼容字符串操作,又能兼容枚举类 |
subagent中的任务上下文,也可以进行自定义,以便于添加一些静态prompt中难以捕捉的输入,例如完整消息历史等。官网的文档目前看是有问题的,使用的时候会报错。我看了源代码之后发现,本质上是runtime的注入并没有生效,我是严管按照官网的示例来做的。不知道以后是否会进行修复。
总结
在AI时代,这种AI基础设施的学习非常有必要。尤其是langchain这种基础的库,更是需要学习的重点。但是版本更新实在是太快了,可能连官网自己的文档都不能做到什么错误都没有,所以还是要自己摸索和实践。同时主要关注“它能让我用大模型做什么”,至于原理我想这么复杂的库,可能不像springboot那样好懂,而且版本的更新会导致各种函数的功能和设计完全失效,可能要等稳定下来之后再说了。
参考资料
- 完整教程:一、初识 LangChain:架构、应用与开发环境部署 - clnchanpin - 博客园
- 深入浅出LangChain AI Agent智能体开发教程(一)—认识LangChain&LangGraph本篇分享从L - 掘金
- Messages - Docs by LangChain
- Models - Docs by LangChain
- AI 结构化 JSON 输出:哪些模型支持 & 定价对比(2026年2月) - DevTk.AI
- Tools - Docs by LangChain
- Runnable | langchain_core | LangChain Reference
- Build a RAG agent with LangChain - Docs by LangChain
- Overview - Docs by LangChain
- Agents - Docs by LangChain
- Quickstart - Docs by LangChain
- Multi-agent - Docs by LangChain
- Subagents - Docs by LangChain
- 标题: Langchain快速入门-BlockStack0x001
- 作者: Baobao0824
- 创建于 : 2026-03-15 00:00:00
- 更新于 : 2026-03-17 15:04:45
- 链接: https://blog.baobao0824.top/块叠BlockStack/BS-0x001/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。