原链接https://www.youtube.com/watch?v=5rNk7m_zlAg
写在前面 这一系列是我在学习他人的优质课程(博客文章、视频课程等)时所做的学习笔记,根据我自身的水平来进行学习,同时会进行思维的发散,补充原文中没有提到或者有错误的地方。同时也会进行经常性的更新和整理,让它和我的当下的状态更加契合。
这是油管上的SpringBoot教程的第三部分,应该讲的是Spring Data JPA的内容。
PostgreSQL 首先为了方便Springboot与数据库沟通,我们需要先安装一个数据库。本视频作者使用的是PostgreSQL。PostgreSQL(常简称为 Postgres)是一款功能强大的开源对象-关系型数据库系统(ORDBMS)。它以其稳定性、数据完整性、丰富的功能集以及对标准的高度兼容性而闻名,常被企业用于替代昂贵的商业数据库(如Oracle)。和MySQL相比,他的SQL语法严格,功能全面,偏向学院派,重视对JSON的支持非常强。我们直接来到它的官网 进行下载就可以了。说实话这是我第一次听说这个数据库,希望他能够比mySQL更好用,以后的个人项目就都用这个了。
同时他也演示了如何用Docker安装,我不太会用docker就先放下了,等到学会docker之后再弄。
安装设置完密码之后就可以连接了,它的默认用户名是postgres,默认端口是5432,和mysql一样的连接方式,可以查看数据库。视频中直接用idea查看数据库了,如果你手中有其他的软件,例如Navicat或者datagrip,也是可以的。同时视频作者又推荐了一款叫做DBeaver的免费软件,我目前是不需要用的。
如果我们要使用Spring data JPA,我们首先要去添加对应的依赖spring-boot-start-data-jpa。同时,在视频中由于作者还没有配置数据库的url,这导致他启动时就会报错Faild to configure a DataSource,不过我们目前的版本比较新,不会出这些问题。
同时在后续的视频教程中,会将application.properties替换成更广泛使用的application.yml。同时添加对应的属性值。
1 2 3 4 5 6 spring: datasource: url: jdbc:postgresql://localhost:5432/demo_db username: postgres password: 123456
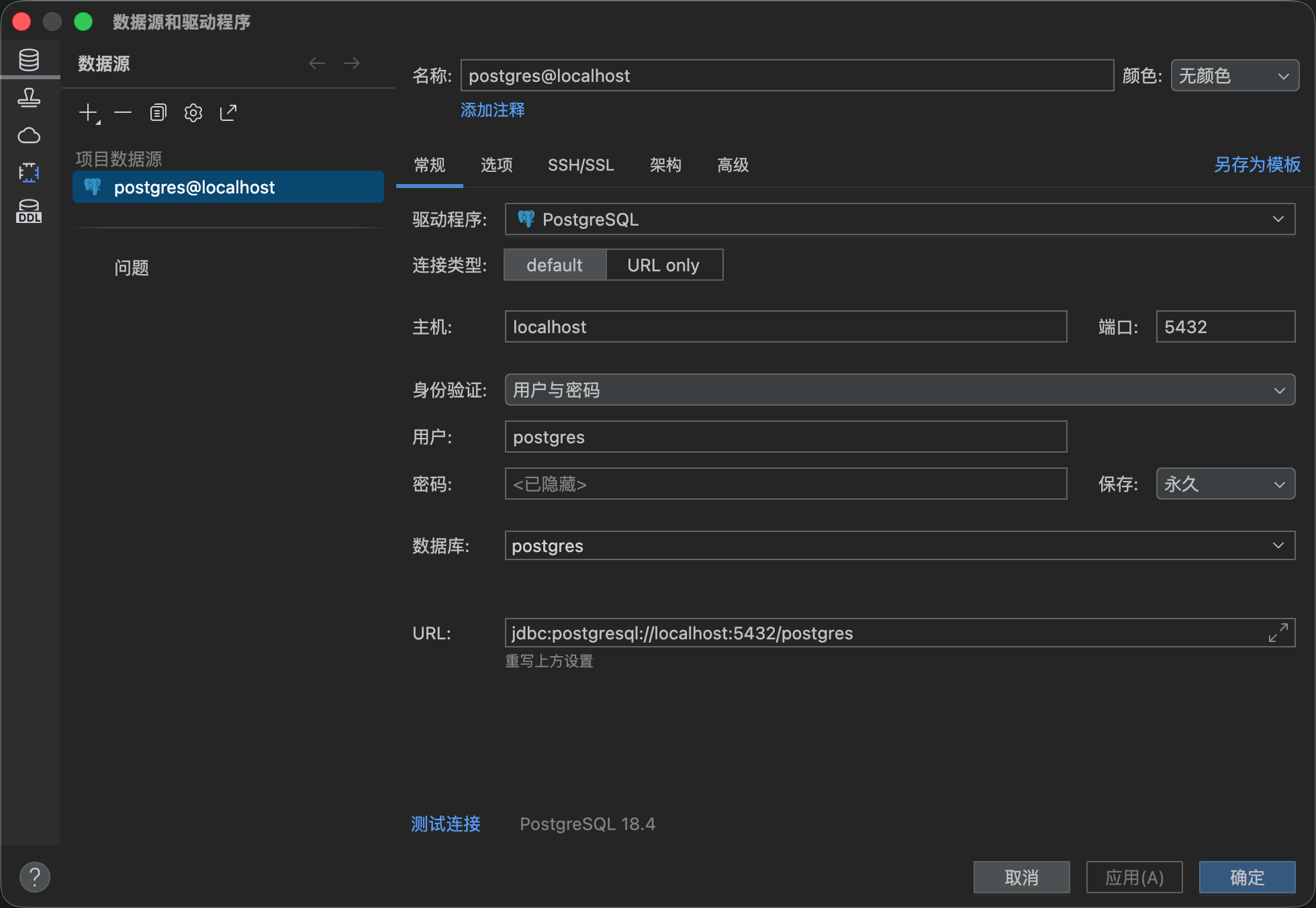
这个URL从哪里获取呢?直接在你项目的数据源属性中即可获取。
直接复制下方的URL即可
同时,连接数据库需要一个驱动,为了使用postgreSQL的驱动,我们还需要添加一个新的依赖,就是postgresql,同时要保证他在运行时才提供。pom文件需要添加的内容如下:
1 2 3 4 5 6 <dependency > <groupId > org.postgresql</groupId > <artifactId > postgresql</artifactId > <scope > runtime</scope > </dependency >
因此此时整个application.yml文件看起来像这样:
1 2 3 4 5 6 7 spring: datasource: url: jdbc:postgresql://localhost:5432/demodb username: postgres password: 123456 driver-class-name: org.postgresql.Driver
点击运行会发现报错了,说Unable to obtain isolated JDBC connection [FATAL: database "demo_db" does not exist] [n/a]因为我们还没有创建对应名称的数据库。创建好之后,在idea里好public架构即可。
社区版idea不能直接在里面创建数据库,所以我是在datagrip里创建的
接下来,我们在SpringPracticeApplication.java所在目录里创建Student类,来模拟数据库的第一张表。学生类的内容如下所示。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 public class Student { private Integer id; private String firstname; private String lastname; private String email; private int age; public Student (int age, String lastname, String firstname, String email) { this .age = age; this .lastname = lastname; this .firstname = firstname; this .email = email; } public Integer getId () { return id; } public void setId (Integer id) { this .id = id; } public String getFirstname () { return firstname; } public void setFirstname (String firstname) { this .firstname = firstname; } public String getLastname () { return lastname; } public void setLastname (String lastname) { this .lastname = lastname; } public String getEmail () { return email; } public void setEmail (String email) { this .email = email; } public int getAge () { return age; } public void setAge (int age) { this .age = age; } }
实际上,Spring Data JPA是一个可以让你不写sql语句就能操作数据库的库,他能够将数据库中的表映射成类,将SQL语句映射成代码。为了让JPA能够将一个类转换成表中的实体,我们的类需要一个空参的构造函数,然后给类加上@Entity注解,然后要指定一个主键,给主键所代表的字段添加@Id注解。上述两个注解都来自jakarta.persistence库。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Entity public class Student { @Id private Integer id; private String firstname; private String lastname; private String email; private int age; public Student () { } }
那么如何能让他们来自动生成数据表呢?实际上,JPA的全称是Java Persistence API,只是一套标准,他最常用的实现就是Hibernate库。那么我们就可以通过配置spring.jpa.hibernate.ddl-auto属性的值来告诉Hibernate在应用启动时该如何处理数据库的表结构。可选值一般有以下几个。
配置值
行为
none什么都不做(推荐生产)
validate只校验实体与表结构是否一致
update自动更新表结构(新增字段)
create每次启动都删表再建表
create-drop启动建表,关闭时删表
因为我们还在早期的开发,所以选择create即可。同时我们也添加了一些其他的属性,我们先罗列出来然后进行一一介绍。
1 2 3 4 5 6 7 8 9 10 11 12 spring: jpa: hibernate: ddl-auto: create show-sql: true database: postgresql database-platform: org.hibernate.dialect.PostgreSQLDialect properties: hibernate: format_sql: true
spring.jpa.show-sql会决定你在数据库操作的时候是否把SQL语句输出到控制台中。spring.jpa.database决定了你用什么数据库,比如这里是postgreSQL。spring.jpa.database-platform是你所用的SQL方言,这里用的就是postgreSQL的方言。spring.jpa.properties.hibernate.format_sql决定了在控制台输出SQL语句的时候是否进行格式化。
然后在应用运行后,我们会发现控制台输出。
Hibernate:
create table student (
age integer not null,
id integer not null,
email varchar(255),
firstname varchar(255),
lastname varchar(255),
primary key (id)
)
同时我们也可以看到数据库中新建了一个student表。
不过目前还是空表,还没有任何数据
如果我们不想用student作为表名,那么可以添加一个@Table注解。这是@Table的源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 @Target(TYPE) @Retention(RUNTIME) public @interface Table { String name () default "" ; String catalog () default "" ; String schema () default "" ; UniqueConstraint[] uniqueConstraints() default {}; Index[] indexes() default {}; CheckConstraint[] check() default {}; String comment () default "" ; String options () default "" ; }
那么我们会发现如果我们修改name的值就可以修改对应的数据表名称。例如
1 2 3 4 5 6 @Entity @Table(name = "T_STUDENT") public class Student { }
此时,数据表的名称就变成了t_student。
同时,如果我们想自定义列名的话,就可以在字段前面添加@Column注解。这个注解的源码如下(注释已翻译)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 @Target({METHOD, FIELD}) @Retention(RUNTIME) public @interface Column { String name () default "" ; boolean unique () default false ; boolean nullable () default true ; boolean insertable () default true ; boolean updatable () default true ; String columnDefinition () default "" ; String options () default "" ; String table () default "" ; int length () default 255 ; int precision () default 0 ; int scale () default 0 ; int secondPrecision () default -1 ; CheckConstraint[] check() default {}; String comment () default "" ; }
例如
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @Entity @Table(name = "T_STUDENT") public class Student { @Id private Integer id; @Column( name = "c_fname", length = 20 ) private String firstname; private String lastname; @Column(unique = true) private String email; private int age; @Column( updatable = false ) private String some_column; }
此时,对应firstname的列就变成了c_fname,同时对应的长度从255变成了20。同时电子邮件也不能重复了。对于some_column列,他将不能再被更新。
还有一个问题,我们光添加了id作为主键,现在插入数据的时候还是需要手动输入ID,这非常的不方便。还好jakarta.persistence给我们提供了@GeneratedValue注解。它的源码如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 @Target({METHOD, FIELD}) @Retention(RUNTIME) public @interface GeneratedValue { GenerationType strategy () default AUTO; String generator () default "" ; }
可以发现,这个注解仅适用于单一主键,不适用于派生主键的数据表。默认的生成规则是AUTO。除了这个还有其他规则吗?有的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public enum GenerationType { TABLE, SEQUENCE, IDENTITY, UUID, AUTO }
这个太不说人话了,让我们说中文。
AUTO,交给JPA决定,默认的,不推荐生产环境。IDENTITY,使用数据库自增,适用于MySQL和SQL Server。SEQUENCE,使用数据库序列,适用于Oracle和PostgreSQL。TABLE,使用中间表模拟序列,很少使用。UUID,由 Hibernate 在应用层自动生成 UUID v4 字符串,适用于 分布式系统 / 微服务。
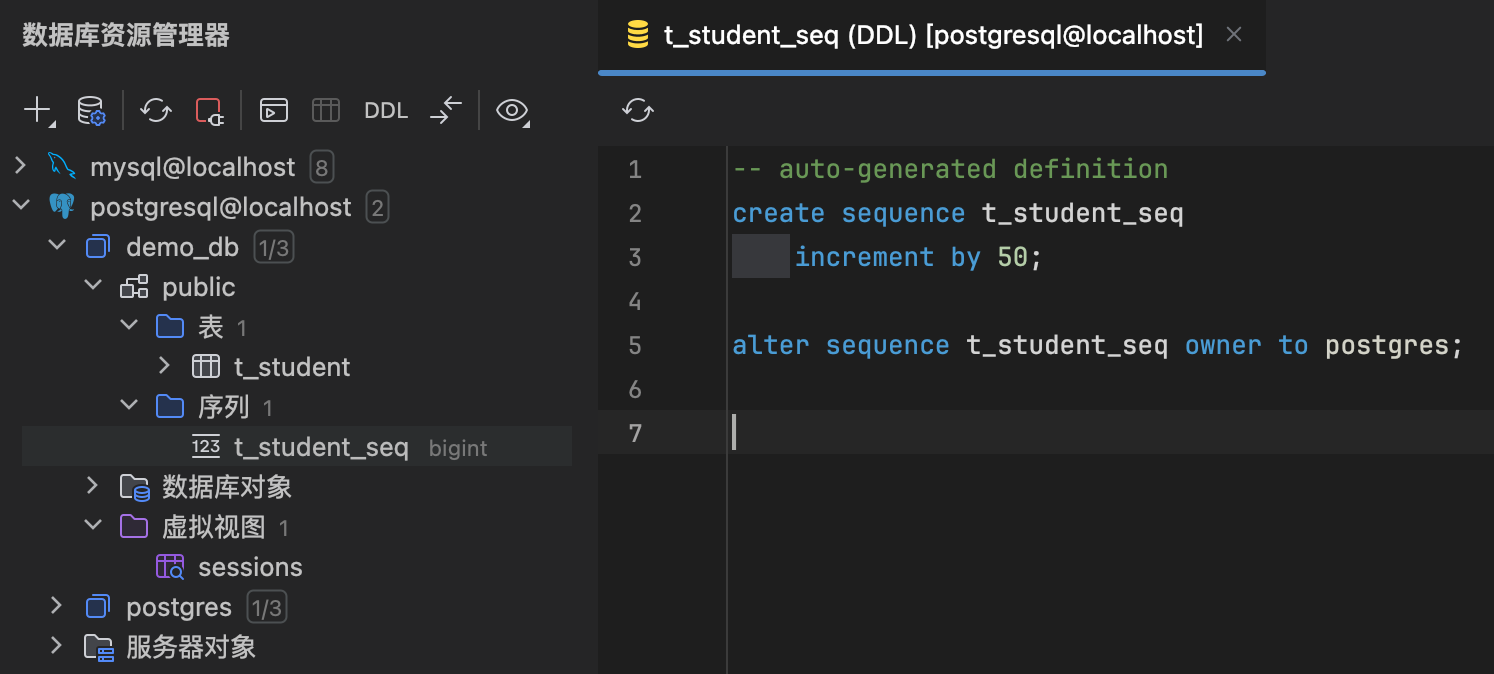
给id添加@GeneratedValue注解,启动应用,出现了一行输出Hibernate: create sequence t_student_seq start with 1 increment by 50。也就是说他选择了适合于PostgreSQL的SEQUENCE方法。同时在对应的数据表中创建了一个序列。
说起来这种对应的SQL语句是存在什么文件里的
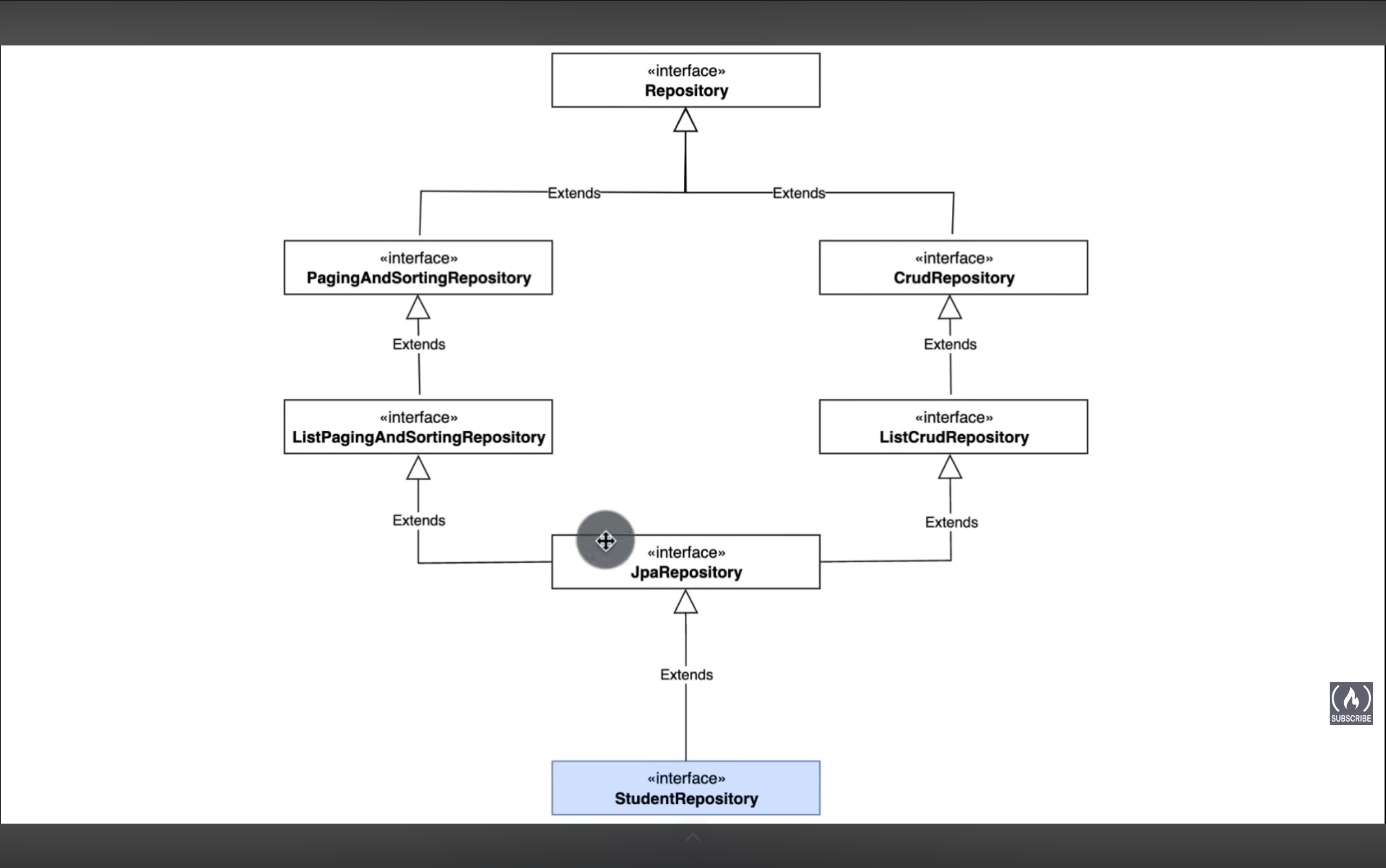
CRUD 接下来我们就可以学习如何将数据持久化到数据库了,也就是增删改查。Spring为我们提供了很多的接口,最终都由JpaRepository来继承,而我们的StudentRepository也继承自JpaRepository。
所有相关的接口继承示意图
我们在SpringPracticeApplication所在目录中创建一个接口StudentRepository,让它继承自JpaRepository。
1 2 3 public interface StudentRepository extends JpaRepository <Student, Integer> {}
JpaRepository接口需要接受两个泛型参数,第一个代表着实体所对应的类型(这里自然是Student),而第二个代表着id的类型(这里是Student类对应的id类型,即Integer)除此之外什么都不用添加了,JPA会自动进行。
接下来我们就需要让它插入一些数据了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @RestController public class FirstController { public FirstController (StudentRepository repository) { this .repository = repository; } private final StudentRepository repository; @PostMapping("/students") public Student post ( @RequestBody Student student ) { return repository.save(student); } }
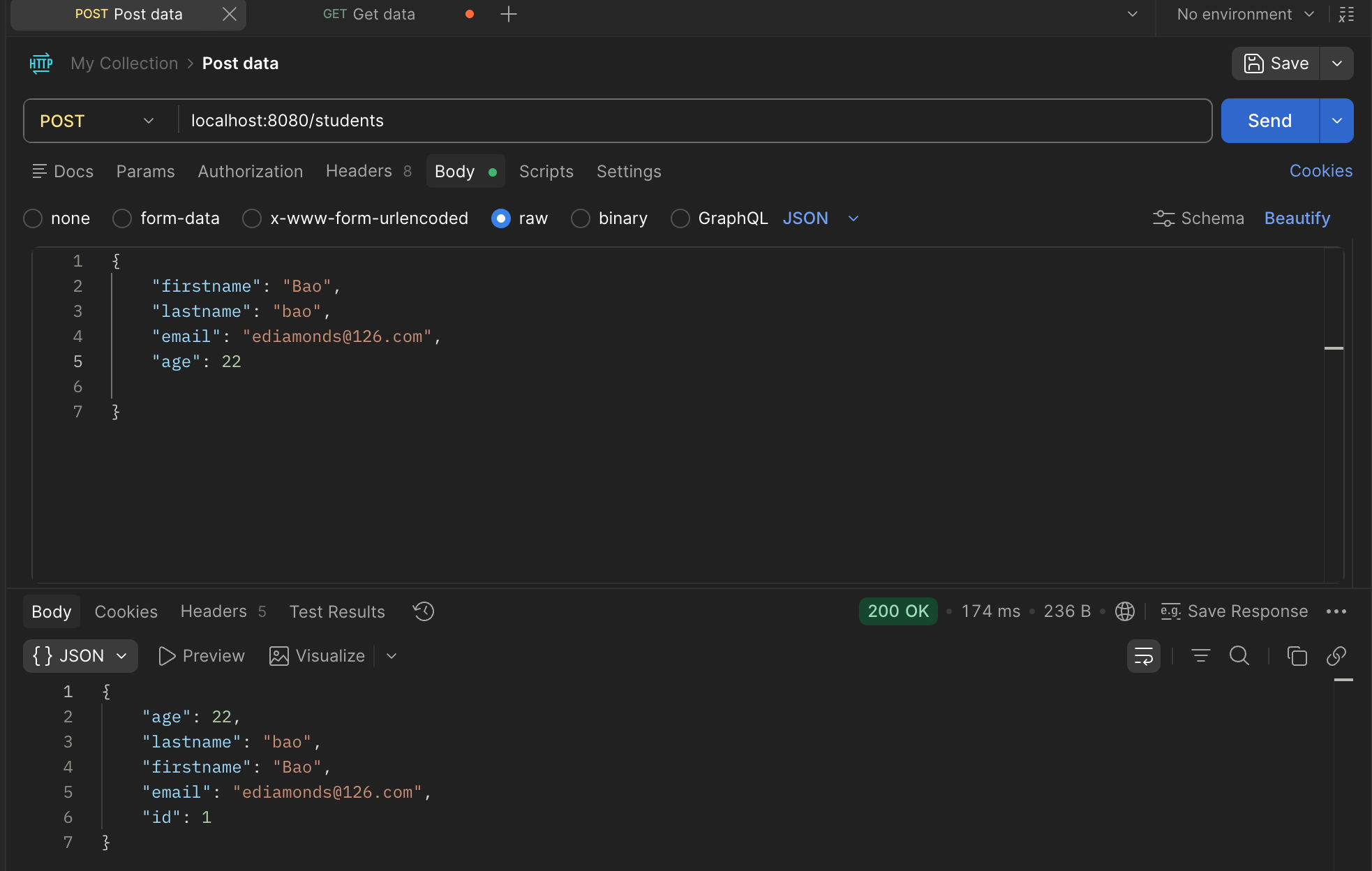
我们直接利用构造函数注入,由于接口是不能new的,因此一个继承了JpaRepository的接口,Spring Data JPA会自动生成一个实现类,然后将其放进容器中。函数体直接调用save方法存入实体,返回刚刚保存的实体。然后就可以让postman发报文了。
现在显示发送成功了
回到数据库,我们发现确实有一个新的数据。我们在插入一个,会发现id能够正常自增(刚才输入的时候如果让邮箱重复的话,就会抛出错误org.postgresql.util.PSQLException: ERROR: duplicate key value violates unique constraint "t_student_email_key"但是ID不会卡到2而是3)这些检查工作是由Hibernate来做的。
接下来我们添加两个方法,分别是查找所有学生,以及根据ID查找特定的学生(他又把视频放反了)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @RestController public class FirstController { @GetMapping("/students") public List<Student> findAllStudent () { return repository.findAll(); } @GetMapping("/students/{student-id}") public Student findStudentById ( @PathVariable("student-id") Integer id ) { return repository.findById(id) .orElse(new Student ()); } }
重启程序后,我们尝试根据id对学生进行查找(为了不再重新造数据,我们将spring.jpa.hibernate.ddl-auto属性设置为none),直接访问localhost:8080/students/1,可以成功返回。同时如果我们直接不加id,就能获取到所有的学生,是一个JSON数组。但是如果我们访问一个不存在的学生例如localhost:8080/students/20,那么它就会新建一个学生,返回
1 2 3 4 5 6 7 { "age" : 0 , "lastname" : null , "firstname" : null , "email" : null , "id" : null }
当然了数据库里面是没有这个空学生的,因为并没有执行repository.save方法。
接下来我们来学习如何进行自定义查询。在自定义查询中,StudentRepository继承的方法就不够用了,我们需要给它一个自定义的方法。
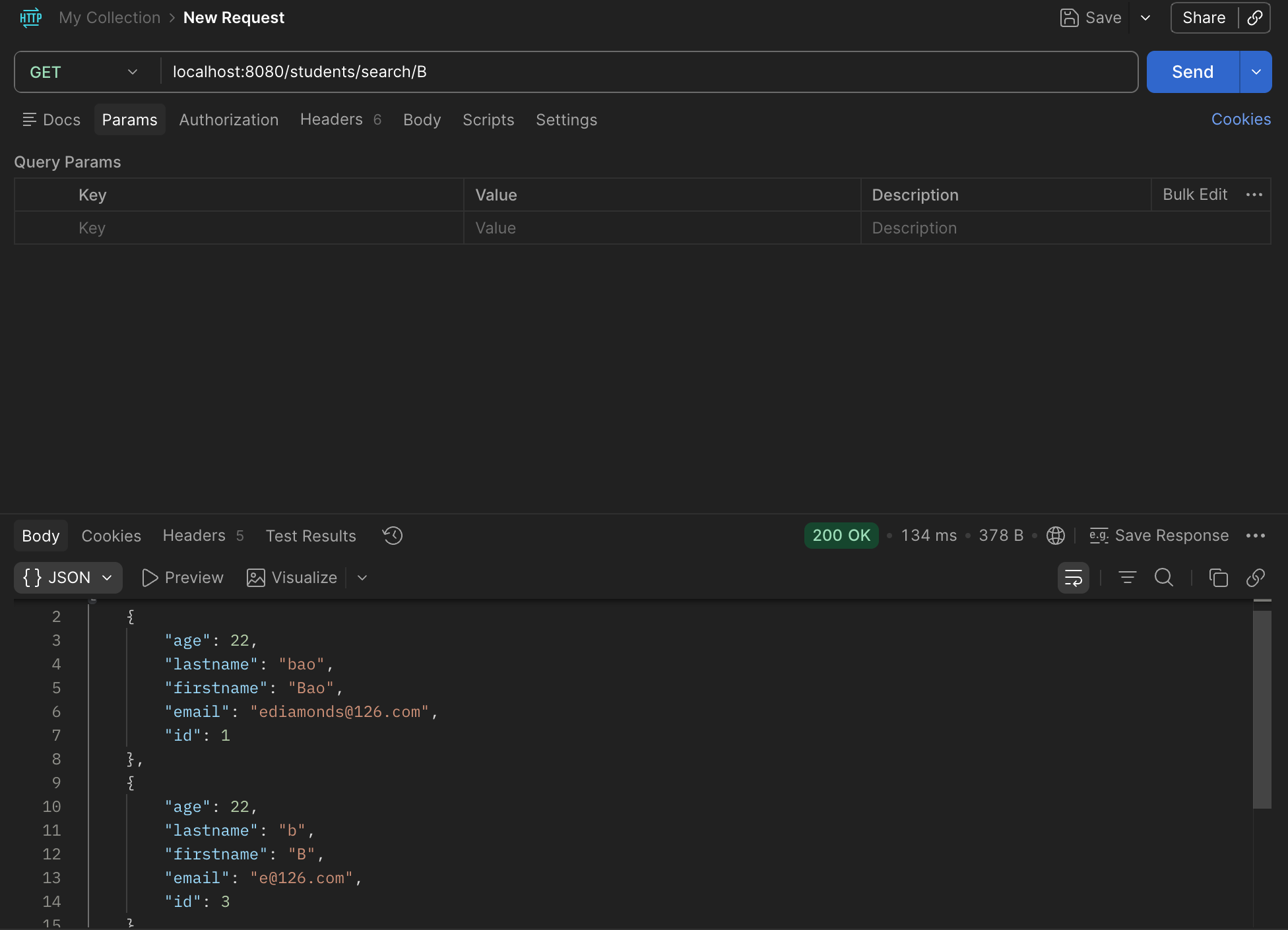
1 2 3 4 public interface StudentRepository extends JpaRepository <Student, Integer> { List<Student> findAllByFirstnameContaining (String p) ; }
是的,因为是接口,所以只需要给方法名和参数就行了,JPA会根据方法的名称来实现具体的数据库操作。我严重怀疑他的效率会比较低,因为不编写SQL语句的话,他还要靠分析方法名来实现这个功能。如果我们不用JPA的话,那么就需要手动实现StudentRepository和StudentRepositoryImpl了。
在Spring中,所有的容器最好都直接用接口约束,例如StudentRepository,而具体的实现则在StudentRepositoryImpl中实现。
说实话这东西到底是怎么实现的太牛逼了
注意到,给StudentRepository写方法的时候,用的是Student的成员变量名,而不是类似于c_fname的数据库名,因为那个名字是给数据库用的,只是为了和数据库协调方便,我们java内部还是用自己原来的名字显得更统一。
接下来我们再看看如何删除学生。首先在FirstController中创建一个方法。
1 2 3 4 5 6 7 8 9 10 11 12 @RestController public class FirstController { @DeleteMapping("/students/{student-id}") @ResponseStatus(HttpStatus.OK) public void delete ( @PathVariable("student-id") Integer id ) { repository.deleteById(id); } }
deleteById是JpaRepository接口中本来就有的方法。运行后什么都没有,因为我们这个是void方法,返回200就可以了。
Relationship 既然涉及到数据库实体,那么实体间的联系也是很有必要的。我们先创建一个实体School。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 @Entity public class School { @Id @GeneratedValue private Integer id; private String name; public School () { } public School (String name) { this .name = name; } public Integer getId () { return id; } public void setId (Integer id) { this .id = id; } public String getName () { return name; } public void setName (String name) { this .name = name; } }
同时创建一个StudentProfile类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class StudentProfile { @Id @GeneratedValue private Integer id; private String bio; public StudentProfile () { } public StudentProfile (String bio) { this .bio = bio; } public Integer getId () { return id; } public void setId (Integer id) { this .id = id; } public String getBio () { return bio; } public void setBio (String bio) { this .bio = bio; } }
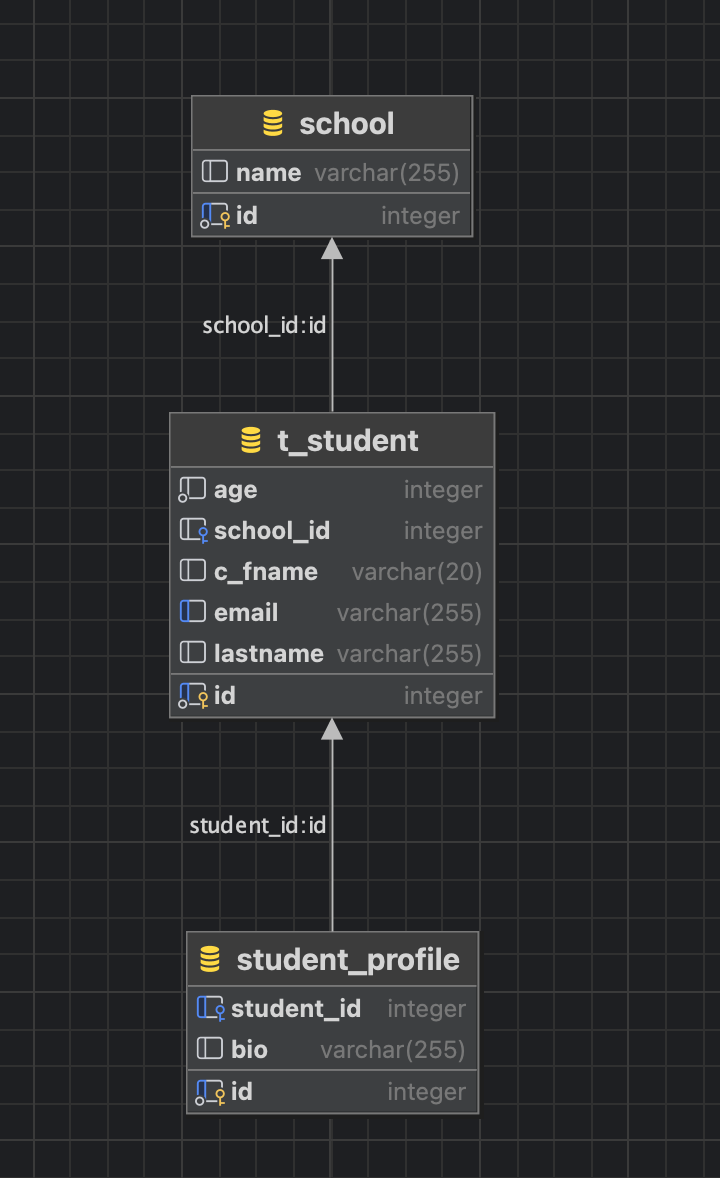
这几个类的实体联系是这样的:Student对StudentProfile是一对一(一个学生只有一份档案),School和Student是一对多(多个学生可以在一个学校中学习)。
首先我们创建学生和学生档案的一对一联系。对应的两个类的修改如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 @Entity public class StudentProfile { @Id @GeneratedValue private Integer id; private String bio; @OneToOne @JoinColumn( name = "student_id" ) private Student student; } @Entity @Table(name = "T_STUDENT") public class Student { @Id @GeneratedValue private Integer id; @Column( name = "c_fname", length = 20 ) private String firstname; private String lastname; @Column(unique = true) private String email; private int age; @OneToOne( mappedBy = "student", cascade = CascadeType.ALL ) private StudentProfile studentProfile; }
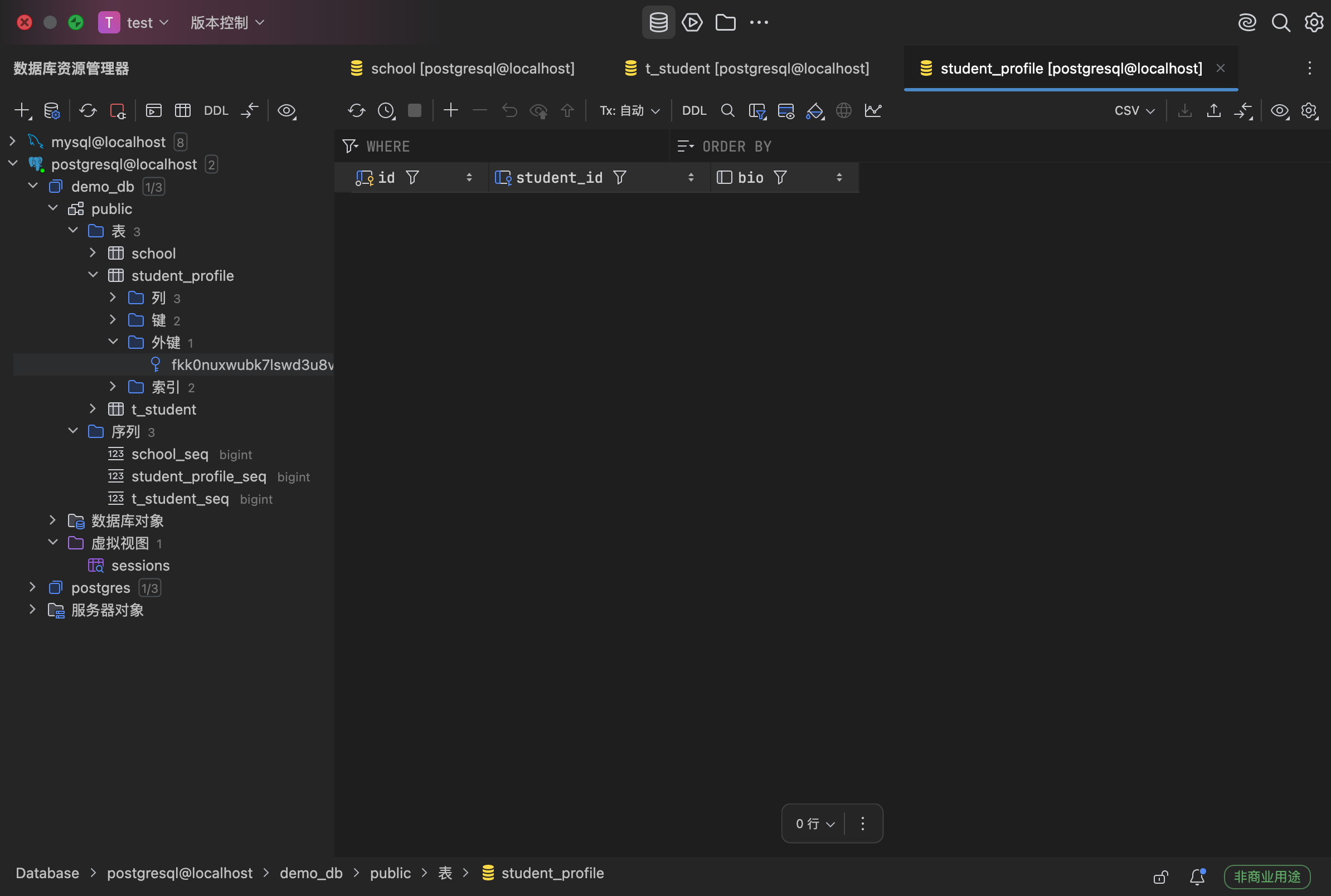
这段代码写完后,学生数据库结构为id,c_fname,lastname,email,age,学生档案数据库结构为id,bio,student_id,最后的student_id是外键。@JohnColumn注解所在的是关系拥有方,负责维护处理在学生档案的外键列,而学生里面的mappedBy="student"说明外键不在这边,在对面。如果不写mappedBy,那么Hibernate会认为两边都要建立外键,两张表互相指向对方,就会报错。说实话到这里我已经认为JPA的缺点暴露无遗了:数据库设计居然在java代码里完成,那岂不是数据库随便被乱改了。
我们可以清楚地看到学生档案表里有一个外键
接下来我们给School数据库添加一对多的联系。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 @Entity public class School { @Id @GeneratedValue private Integer id; private String name; @OneToMany( mappedBy = "school" ) private List<Student> students; } @Entity @Table(name = "T_STUDENT") public class Student { @Id @GeneratedValue private Integer id; @Column( name = "c_fname", length = 20 ) private String firstname; private String lastname; @Column(unique = true) private String email; private int age; @OneToOne( mappedBy = "student", cascade = CascadeType.ALL ) private StudentProfile studentProfile; @ManyToOne @JoinColumn( name = "school_id" ) private School school; }
这个也很有意思,标准的一对多设计,外键应该在学生表中,学校数据表不负责外键,mappedBy指向的是学生表中的school属性。
dataGrip生成的实体联系图
总结 如果后续要继续学习SpringBoot的话,那么我肯定是不会看这个视频了,因为JPA确实和国内现在的互联网技术脱节了。现在是Mybatis的天下,这种java代码控制的数据库确实没有人在使用了。